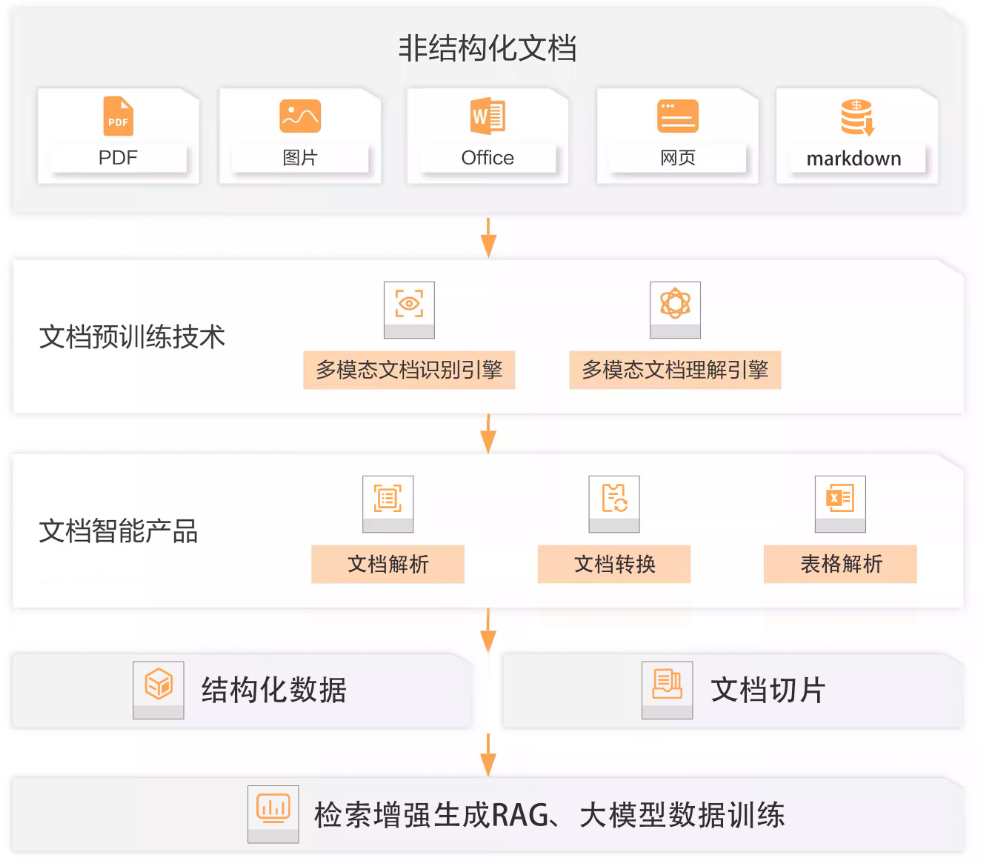
RAG基础知识简记
1.大模型应用开发的三种模式:Prompt,RAG,模型Fine-tuning
Prompt场景:问题没问清楚
RAG场景:缺少专业知识,背景知识
模型Fine-tuning:模型能力不足
以上三种模式结合使用。
2.RAG: Retrieval-Augmented Generation, 检索增强生成
检索结果作为上下文内容,给大模型整合输出,提高时效性和准确性。
检索:向量检索
增强:prompt中放入检索内容,
生成:大模型生成结果
本质:重新构建了一个新的Prompt。
3.RAG 整体流程
USER query(Embedding)-> Vector DB ->Retrieval system-Retrieval Data->Rerank->Filter->Generates final answer.
Step1. 数据预处理,构建索引库(知识库构建-文档分块chunks-向量化处理[嵌入模型BGE,M3E,Chinese-Alpaca-2等])
Step2. 检索阶段(查询处理,重排序)
Step3. 生成阶段(构建prompt,获取结果)
RAG在不同阶段提升质量的实践
- 数据准备环节,阿里云考虑到文档具有多层标题属性且不同标题之间存在关联性,提出多粒度知识提取方案,按照不同标题级别对文档进行拆分,然后基于Qwen14b模型和RefGPT训练了一个面向知识提取任务的专属模型,对各个粒度的chunk进行知识提取和组合,并通过去重和降噪的过程保证知识不丢失、不冗余。最终将文档知识提取成多个事实型对话,提升检索效果;
- 知识检索环节,哈啰出行采用多路召回的方式,主要是向量召回和搜索召回。其中,向量召回使用了两类,一类是大模型的向量、另一类是传统深度模型向量;搜索召回也是多链路的,包括关键词、ngram等。通过多路召回的方式,可以达到较高的召回查全率。
- 答案生成环节,中国移动为了解决事实性不足或逻辑缺失,采用FoRAG两阶段生成策略,首先生成大纲,然后基于大纲扩展生成最终答案。


发表评论